Rule box category Work with HTML
Learn how to use the rule box category Work with HTML to extract your product data from HTML code in Productsup.
Introduction
The category Work with HTML contains all rule boxes that can help you extract desired data from an HTML body by ID, tag name, or XPath.
This rule box category contains the following rule boxes:
HTML getElementById lets you extract data from HTML code using IDs defined in the tags.
HTML getElementByTagName lets you extract data from HTML code using tag names.
HTML getElementByXpath lets you extract data from HTML code using paths to relevant elements within the code.
The rule boxes in the category Work with HTML help you extract the needed data from the crawled HTML code after using the Data Crawler data service. If this is your case, you need to take the steps described in Prerequisites before using these rule boxes. If your use case doesn't involve the Data Crawler data service, you can skip these steps and use the rule boxes of this category to extract data from HTML.
Tip
Extracting information from HTML code is a technically advanced task. If you require assistance, contact your in-house developers or Customer Success Manager or reach out to support@productsup.com.
Prerequisites
If you want to use the rule box category Work with HTML to extract data from crawled HTML code after using the Data Crawler data service, first you need to:
Set up and run the Data Crawler data service. See Crawl product landing pages with the Data Crawler.
Map the attribute ___service_datacrawler_data containing your source HTML code to an intermediate or export attribute where you can apply the needed rule boxes.
Identify the elements in the crawled HTML code that you need to extract data from:
Open one of your crawled product pages and find the data you want to extract on the page.
To access the HTML code of the needed page element, use your browser's functionality to open the developer's panel and inspect the page element containing your data.
In the HTML code of the needed page element, find the tag that stores the needed data and copy the tag's name, featured ID, or Xpath. You can later choose a suitable rule box based on which element you can use to access the right HTML tag within your source code. Here are examples of these elements:
A tag's ID
The tag
<div>has anidattribute containing the valuetop-pagerin the following code snippet:<div id="top-pager"> <ul class="pager"> <li class="previous">...</li> <li class="next">...</li> </ul> </div>If you find a suitable tag ID that uniquely identifies the tag containing the data you want to extract, you can use the rule box HTML getElementById.
A tag's name
The tag named
<ul>contains two list items<li>in the following code snippet:<div id="top-pager"> <ul class="pager"> <li class="previous">...</li> <li class="next">...</li> </ul> </div>If you find the name of a suitable tag that contains the data you want to extract, you can use the rule box HTML getElementByTagName.
Xpath
An Xpath is the full path to a chosen element in the code structure. Find the needed tag in the developer's panel of your browser, open the context menu, and select Copy XPath. For example, the first
<li>tag in the following code snippet has the Xpath/div/ul/li[1].<div id="top-pager"> <ul class="pager"> <li class="previous">...</li> <li class="next">...</li> </ul> </div>If you find the needed Xpath that identifies the location of the code element containing the data you want to extract, you can use the rule box HTML getElementByXpath.
Tip
Sometimes, the crawled code of your product page can differ from the code of that page accessed on your live website in the developer's panel of your browser. The Xpaths may vary as well. To get the Xpath to the needed element in your crawled code, you can:
Copy your crawled code and paste it into a local file on your computer.
Save the file as an HTML.
Open the HTML file in your browser and proceed using the developer's panel.
HTML getElementById
The rule box HTML getElementById extracts data from HTML code using a specific ID defined in a tag. If the rule box doesn't find the provided tag ID in a value, it empties the value.
Take the steps from Add a rule box to add the HTML getElementById rule box.
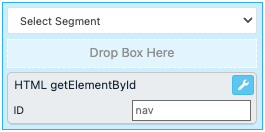
In ID, enter the tag ID that uniquely identifies the tag containing the data you want to extract.
Select Save.
For example, you have the following values in the html_code attribute and want to extract product names from these HTML bodies. You can achieve this with the HTML getElementById rule box by entering productName as the tag ID:
html_code (before) | html_code (after) |
|---|---|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> Flat leather sandals with a bow</h1>
</div> |
|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> High-heel sandals with a buckle</h1>
</div> |
|
HTML getElementByTagName
The rule box HTML getElementByTagName extracts data from HTML code using a specific name of a tag. If the rule box doesn't find the provided tag name in a value, it empties the value.
Take the steps from Add a rule box to add the HTML getElementByTagName rule box.
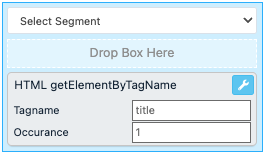
In Tagname, enter the name of the tag containing the data you want to extract.
If a value contains multiple matches of the defined tag, you can enter a number in Occurance to let the rule box know which occurrence of the defined tag you want to extract:
Enter 0 or leave the field empty to extract the first occurrence of the tag.
Enter 1 to extract the second occurrence of the tag.
Note
If a value contains only one occurrence of the provided tag name, but you want to extract the second one, the rule box empties the value.
Select Save.
For example, you have the following values in the html_code attribute and want to extract product names from these HTML bodies. You can achieve this with the HTML getElementByTagName rule box by entering div as the tag name:
html_code (before) | html_code (after) |
|---|---|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> Flat leather sandals with a bow</h1>
</div>
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> High-heel sandals with a buckle</h1>
</div> |
|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> High-heel sandals with a buckle</h1>
</div> |
|
HTML getElementByXpath
The rule box HTML getElementByXpath extracts data from HTML code using the Xpath leading to the element in the code that stores your data. If the rule box doesn't find the provided Xpath in a value, it empties the value.
Take the steps from Add a rule box to add the HTML getElementByXpath rule box.
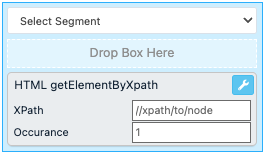
In XPath, enter the path leading to the element in the code that contains the data you want to extract.
If a value contains multiple matches of the defined path, you can enter a number in Occurance to let the rule box know which occurrence of the defined path you want to extract:
Enter 0 or leave the field empty to extract the first occurrence of the path.
Enter 1 to extract the second occurrence of the path.
Note
If a value contains only one occurrence of the provided path, but you want to extract the second one, the rule box empties the value.
Select Save.
For example, you have the following values in the html_code attribute and want to extract product names from these HTML bodies. You can achieve this with the HTML getElementByXpath rule box by entering //div/h1 as the Xpath:
html_code (before) | html_code (after) |
|---|---|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> Flat leather sandals with a bow</h1>
</div>
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> High-heel sandals with a buckle</h1>
</div> |
|
<div id="productName" class="align-top product-name-container">
<h1 class="product-name title"> High-heel sandals with a buckle</h1>
</div> |
|
Further work with the crawled data
After extracting the needed data using the rule box category Work with HTML, you may need to drill further into your HTML data. For example, you can extract data via split strings or regex.
Extract data via split strings
To split the HTML code into bits and preserve only the needed parts of it, you can use the following split string rule boxes:
Split String splits a string into parts and removes the unneeded parts.
Split String for PLA splits a string into parts and removes the unneeded parts. If the rule box finds no splitter character in a string, it empties the string.
Split String & Filter splits a string into parts, removes the unneeded data, and trims the length of your resulting values according to a character limit.
Split String and Count Items splits a string into parts, counts them, and replaces the current value with the number of data parts found in it.
See Rule box category Change string length for more information on split string rule boxes.
Extract data via regex
To search your HTML data for information that matches specific search patterns defined using regular expressions, you can use the following regex rule boxes:
Preg Replace searches your data for regex matches and replaces the matches with values of your choice.
Preg Match searches your data for a regex match, preserves the matching part of the data, and removes the rest of the string. The Preg Match rule box stops scanning a string as soon as it finds a match, so the rule box saves only the first match if there are multiple matches in a string.
Preg Match All has the same functionality as the Preg Match rule box, but it lets the platform find and preserve multiple regex matches within a string.
Set Value if Match (Regex) specifies the values of one attribute based on the results of a regex search performed in another attribute.
See Rule box category Use regular expressions for more information on regex rule boxes.